こんにちは。
Legoliss データアナリストの音嶋健斗です。
このブログでは、データマーケティングにまつわる様々な情報をお届けします。

■はじめに
AWS-Athenaとは、S3上のデータに対して、クエリ(SQL)を利用してデータの分析を行うことができるフルマネージド(サーバーレス)サービスです。
S3に設置するファイル形式は「CSV」「TSV」「JSON」が対応していて、ファイルを設置した後、Athena上でファイルの中身の「引用符」「文字コード」「ヘッダー有無」を考慮してCreate-Tableする必要があります。
Create-Tableについては、Athena特有のルールがあるため少し複雑です。なのでパターンをまとめました。
今回はファイル形式を「CSV」に絞って説明していきます。
参考文献
・Athena構築手順
・AWSドキュメント
■本記事の内容
・各用語の簡単な説明
・対応表の説明
・まとめ
■各用語の簡単な説明
・CSV:文字と文字の区切りが「,(カンマ)」で区切られているファイル形式です。
・引用符:文字のはじめと終わりに囲む記号で、「"(二重引用符)」がよく利用されます。
・文字コード:文字表記のバイト表現のことで、UTF8やSJISがよく利用されます。
・ヘッダー有無:ファイルの一行目にカラムの名前が有るか無いかです。
■対応表の説明
引用符、文字コード、ヘッダーはよく利用するものだけを絞っています。
AthenaのCreate-Tableデフォルト設定が、「引用符なし」「文字コードUTF8」「ヘッダー無」になり、デフォルトの場合は省略することが可能です。今回の対応表では省略可能なものは省略しています。
また、これ以外のファイル形式はあまり見かけませんが、そのファイルもCreate-Tableしたい場合は公式ドキュメントをご参照下さい。
| 引用符 | 文字コード | ヘッダー | ファイル内容例 | Create-Table | 結果 | 備考 |
| あり (")二重引用符 |
UTF8 | あり | "col1","col2" "123","ひらがな" "abc","カタカナ" |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'skip.header.line.count'='1' ); |
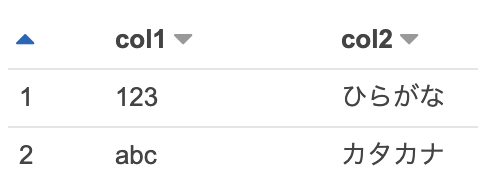
|
|
| あり (")二重引用符 |
UTF8 | なし | "123","ひらがな" "abc","カタカナ" |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://legoliss-test/csv/'; |
|
|
| あり (")二重引用符 |
SJIS | あり | "col1","col2" "123","ひらがな" "abc","カタカナ" |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim' = ',' ) LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'skip.header.line.count'='1', 'serialization.encoding'='SJIS' ); |
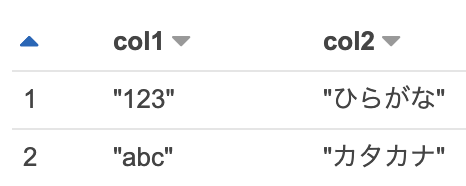
|
「引用符あり」「文字コード:SJIS」の場合は、Create-Tableのみの処理ではできない。まず引用符ありのデータを作り、その後の処理で引用符を削除するSQL処理を実施する。 |
| あり (")二重引用符 |
SJIS | なし | "123","ひらがな" "abc","カタカナ" |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim' = ',' ) LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'serialization.encoding'='SJIS' ); |
|
「引用符あり」「文字コード:SJIS」の場合は、Create-Tableのみの処理ではできない。まず引用符ありのデータを作り、その後の処理で引用符を削除するSQL処理を実施する。 |
| なし | UTF8 | あり | col1,col2 123,ひらがな abc,カタカナ |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'skip.header.line.count'='1' ); |
|
|
| なし | UTF8 | なし | 123,ひらがな abc,カタカナ |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://legoliss-test/csv/'; |
|
|
| なし | SJIS | あり | col1,col2 123,ひらがな abc,カタカナ |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim' = ',' ) LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'skip.header.line.count'='1', 'serialization.encoding'='SJIS' ); |
|
|
| なし | SJIS | なし | 123,ひらがな abc,カタカナ |
CREATE EXTERNAL TABLE tb_name ( col1 string, col2 string ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim' = ',' ) LOCATION 's3://legoliss-test/csv/' TBLPROPERTIES ( 'serialization.encoding'='SJIS' ); |
|
■まとめ
CSV形式のまとめは以上になります。
Athenaを利用することで、データ量が大きいCSVファイルにクエリを書いて分析ができるようになりました。
今後はTSVとJSONについても順に作成していきたいと思います。
<このブログの執筆者>
株式会社Legoliss
データアナリスト 音嶋健斗